Análise de Sentimento com banco de dados real

O objetivo deste projeto é gerar um modelo de Machine Learning para classificar o sentimentos dos usuários em relação às compras de acordo com os reviews dos produtos.
Um sistema de análise de sentimentos com conteúdo textual combina processamento de linguagem natural (PNL/NLP) com técnicas de Machine Learning para conferir pontuações ponderadas de sentimentos à sentenças.
Visto que a inteligência artificial visa simular a estrutura de pensamento dos seres humanos, bem como permitir diálogos complexos entre máquina e humano, o NLP é indispensável para permitir que a máquina compreenda o que está sendo dito e possa estruturar a melhor resposta.
Em suma, a inteligência artificial usa o processamento de linguagem natural para entender a linguagem humana e simulá-la.
Além do NLP, alguns outros conceitos estão incluídos no processamento da Inteligência Artificial, entre eles machine learning e deep learning NLP.
- Entregáveis:
- Data Pipeline para automatizar as etapas de ETL.
- Modelo de classificação que dado um determinado conjunto de teste o modelo consiga retornar a classificação em positivo, negativo ou neutro.
- Relatório com os insights gerados a partir dos dados.
Chamando as primeiras bibliotecas
import numpy as np
import pandas as pd
df_original = pd.read_csv("review.csv") # csv com os dados de review dos usuários
df_original.head()

df_original.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 99224 entries, 0 to 99223
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 review_id 99224 non-null object
1 order_id 99224 non-null object
2 review_score 99224 non-null int64
3 review_comment_title 11568 non-null object
4 review_comment_message 40977 non-null object
5 review_creation_date 99224 non-null object
6 review_answer_timestamp 99224 non-null object
dtypes: int64(1), object(6)
memory usage: 5.3+ MB
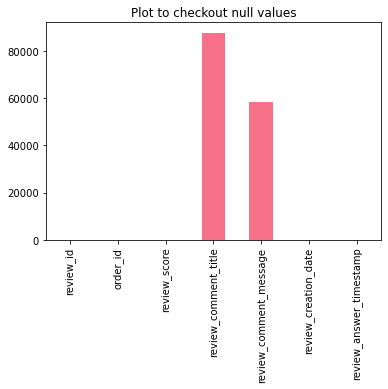
df_original.isnull().sum()
# 99224-58247 = 40977 (58% de valores nulos)
review_id 0
order_id 0
review_score 0
review_comment_title 87656
review_comment_message 58247
review_creation_date 0
review_answer_timestamp 0
dtype: int64
Comparando a quantidade de valores nulos das duas variáveis em plot
import matplotlib.pyplot as plt
df_original.isna().sum().plot(kind = 'bar')
plt.title('Plot to checkout null values')
plt.show()
i- Importando algumas bibliotecas de plotagem
ii- Análise Exploratória
import seaborn as sns
sns.set_palette('husl')
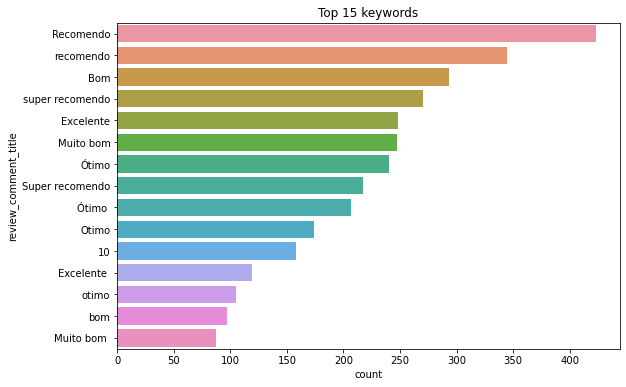
plt.figure(figsize=(9,6))
sns.countplot(y = df_original.review_comment_title, order= df_original.review_comment_title.value_counts().iloc[:15].index)
plt.title('Top 15 keywords')
plt.show()
# As variáveis review_comment_title e review_comment_message são similares, porém a segunda apresenta uma gama maior de dados que podemos análisar com a NLP,
# e também menos dados faltantes
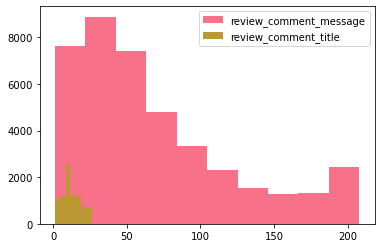
# Analisando a riqueza (em strings) das duas variáveis, para uma análise de sentimentos isso pode ser importante
plt.hist(df_original['review_comment_message'].str.len(), label = 'review_comment_message')
plt.hist(df_original['review_comment_title'].str.len(),label = 'review_comment_title')
plt.legend()
plt.show()
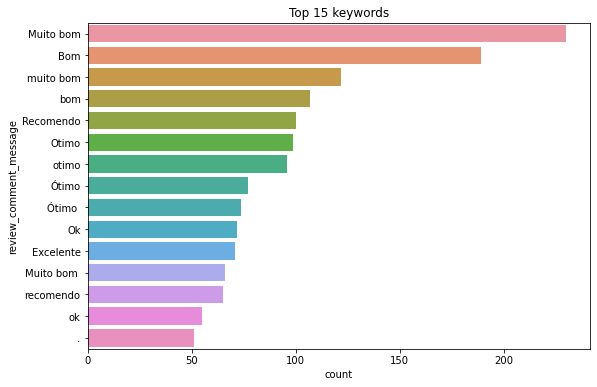
# A variável review_comment_message apresenta 58% de valores faltantes, porém não temos como fazer tratamento desses dados por substituição
# A única alternativa é dropar os dados faltantes e trabalhar com a amostra que temos
sns.set_palette('husl')
plt.figure(figsize=(9,6))
sns.countplot(y = df_original.review_comment_message, order= df_original.review_comment_message.value_counts().iloc[:15].index)
plt.title('Top 15 keywords')
plt.show()
# Vamos primeiro fazer uma cópia da df para não prejudicar a original, caso precisemos dela depois
# Dropando as linhas com dados faltantes
df_copy = df_original
df_copy.dropna(inplace = True)
df_copy.head(10)
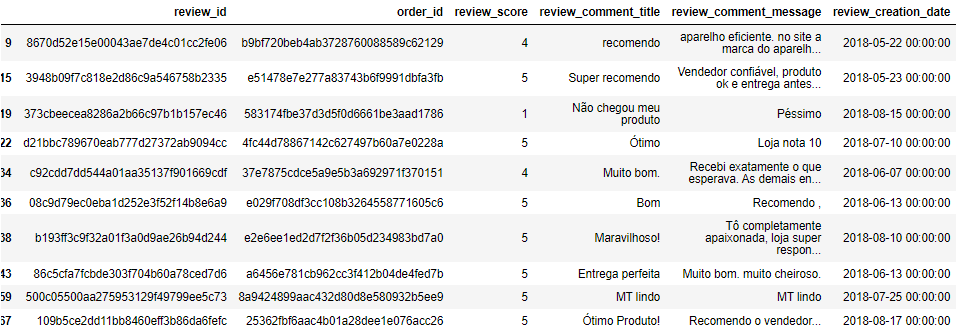
df_copy.info
<bound method DataFrame.info of review_id order_id \
9 8670d52e15e00043ae7de4c01cc2fe06 b9bf720beb4ab3728760088589c62129
15 3948b09f7c818e2d86c9a546758b2335 e51478e7e277a83743b6f9991dbfa3fb
19 373cbeecea8286a2b66c97b1b157ec46 583174fbe37d3d5f0d6661be3aad1786
22 d21bbc789670eab777d27372ab9094cc 4fc44d78867142c627497b60a7e0228a
34 c92cdd7dd544a01aa35137f901669cdf 37e7875cdce5a9e5b3a692971f370151
... ... ...
99187 47e0954e156dac6512c25c6d2ecc1c66 16cbf959cfdb88c47ee2a29303547ec2
99192 0e7bc73fde6782891898ea71443f9904 bd78f91afbb1ecbc6124974c5e813043
99196 58be140ccdc12e8908ff7fd2ba5c7cb0 0ebf8e35b9807ee2d717922d5663ccdb
99197 51de4e06a6b701cb2be47ea0e689437b b7467ae483dbe956fe9acdf0b1e6e3f4
99200 2ee221b28e5b6fceffac59487ed39348 f2d12dd37eaef72ed7b1186b2edefbcd
review_score review_comment_title \
9 4 recomendo
15 5 Super recomendo
19 1 Não chegou meu produto
22 5 Ótimo
34 4 Muito bom.
... ... ...
99187 5 Nota máxima!
99192 4 👍
99196 5 muito bom produto
99197 3 Não foi entregue o pedido
99200 2 Foto enganosa
review_comment_message review_creation_date \
9 aparelho eficiente. no site a marca do aparelh... 2018-05-22 00:00:00
15 Vendedor confiável, produto ok e entrega antes... 2018-05-23 00:00:00
19 Péssimo 2018-08-15 00:00:00
22 Loja nota 10 2018-07-10 00:00:00
34 Recebi exatamente o que esperava. As demais en... 2018-06-07 00:00:00
... ... ...
99187 Muito obrigado,\r\n\r\nExcelente atendimento,b... 2018-05-22 00:00:00
99192 Aprovado! 2018-07-04 00:00:00
99196 Ficamos muito satisfeitos com o produto, atend... 2018-06-30 00:00:00
99197 Bom dia \r\nDas 6 unidades compradas só recebi... 2018-06-05 00:00:00
99200 Foto muito diferente principalmente a graninha... 2018-03-28 00:00:00
review_answer_timestamp
9 2018-05-23 16:45:47
15 2018-05-24 03:00:01
19 2018-08-15 04:10:37
22 2018-07-11 14:10:25
34 2018-06-09 18:44:02
... ...
99187 2018-05-23 00:51:43
99192 2018-07-05 00:25:13
99196 2018-07-02 23:09:35
99197 2018-06-06 10:52:19
99200 2018-05-25 01:23:26
[9839 rows x 7 columns]>
# Droparei as variáveis que acredito não apresentarem influência na análise
df_copy.drop("review_id", axis=1,inplace=True)
df_copy.drop("order_id", axis=1,inplace=True)
df_copy.drop("review_answer_timestamp", axis=1,inplace=True)
df_copy.drop("review_creation_date", axis=1,inplace=True)
df_copy.drop("review_comment_title", axis=1,inplace=True)
df_copy.head()
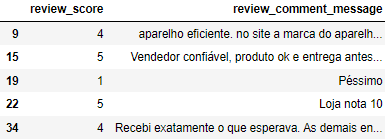
df_copy.review_score.value_counts()
5 5422
1 1789
4 1433
3 737
2 458
Name: review_score, dtype: int64
# O que podemos inferir em relação à variável de Score?
# Temos 5 classes, mais da metade está na melhor classificação, porém a segunda classificação mais frequente está em péssimo
import plotly.express as px
px.pie(df_copy,names='review_score',title='Distribution of Review Score',hole=0.5)
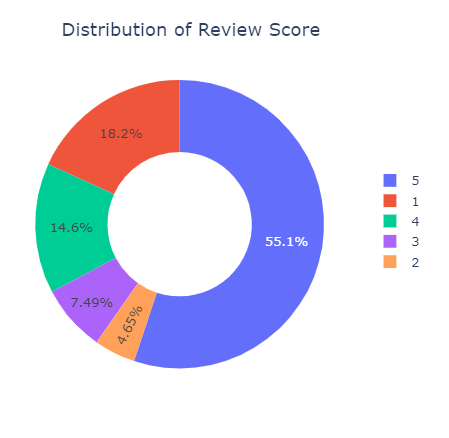
Podemos também analisar o conteúdo de cada review em relação ao score (em ordem ascendente)
1 - Péssimo
2 - Ruim
3 - Neutro
4 - Bom
5 - Excelente
analysis_1 = df_copy[df_copy['review_score'] == 1]['review_comment_message']
print(analysis_1.head(10))
19 Péssimo
167 A peça não serviu
190 Faltou 1 produto e os que recebi 1 veio quebrado
197 aqui está descrevendo como entregue só que ate...
276 Cancelaram a minha compra um dia antes da entr...
332 Boa Noite\r\n\r\né lamentável, esta loja que t...
426 Quando instalei o cartucho de tinta, a minha i...
863 PRODUTO JA CHEGOU COM DEFEITO NÃO FUCIONOU CON...
924 Ainda não recebi o produto...
934 Comprei 2 produtos so mandaram 1 e n mim deram...
Name: review_comment_message, dtype: object
analysis_2 = df_copy[df_copy['review_score'] == 2]['review_comment_message']
print(analysis_2.head(10))
336 A capa protetora não é exatamente o que eu esp...
685 O produto não está nas medidas corretas indica...
818 Penso que deveria haver um modo de se comunica...
1208 Bom dia ... comprei um bebedouro vermelho metá...
1337 Pedi duas carteiras. Uma veio com defeito e ou...
1379 Boa noite na compra diz wireless 150mbs Multil...
2391 Apesar da demora na entrega. No mais foi tudo ...
2407 Eu pedi dois kit e só chegou apenas um o outro...
2546 Eu não recebi minha cortina ainda
2949 Segundo site da Pineng, consta uma relação de ...
Name: review_comment_message, dtype: object
analysis_3 = df_copy[df_copy['review_score'] == 3 ]['review_comment_message']
print(analysis_3.head(10))
131 A entrega foi dividida em duas. Não houve comu...
201 Comecei a usar agora
207 Comprar um produto correto na capa mas interno...
212 Fiz um pedido de 4 garrafas de azeite.Chegaram...
253 Apesar de ter sido entregue rapidamente, subst...
341 No site o produto parece ter melhor qualidade ...
394 recebe apenas 01 peça do produto! estou precis...
455 Fiquei feliz com. O tecido ,mas acho que falto...
726 SOLICITEI DEVOLUÇÃO. PRODUTO COM DEFEITO
969 Muito bom.
Name: review_comment_message, dtype: object
analysis_4 = df_copy[df_copy['review_score'] == 4 ]['review_comment_message']
print(analysis_4.head(10))
9 aparelho eficiente. no site a marca do aparelh...
34 Recebi exatamente o que esperava. As demais en...
166 Se fosse vidro tinha quebrado; veio na caixa ...
324 Tudo rápido e eficiente.
391 O pedido chegou antes do combinado, muito bom.
404 trabalho com profissionalismo das lojas lannis...
493 otimo\r\n
518 Otimo produto porem caro demais !!!
612 Boa compra.
735 Acho que o produto deveria ter um prazo de val...
Name: review_comment_message, dtype: object
analysis_5 = df_copy[df_copy['review_score'] == 5 ]['review_comment_message']
print(analysis_5.head(10))
15 Vendedor confiável, produto ok e entrega antes...
22 Loja nota 10
36 Recomendo ,
38 Tô completamente apaixonada, loja super respon...
43 Muito bom. muito cheiroso.
59 MT lindo
67 Recomendo o vendedor...
79 O kit mochila patrulha canina é lindo!! Meu ne...
90 Super rápido.
108 OK RECOMENDO
Name: review_comment_message, dtype: object
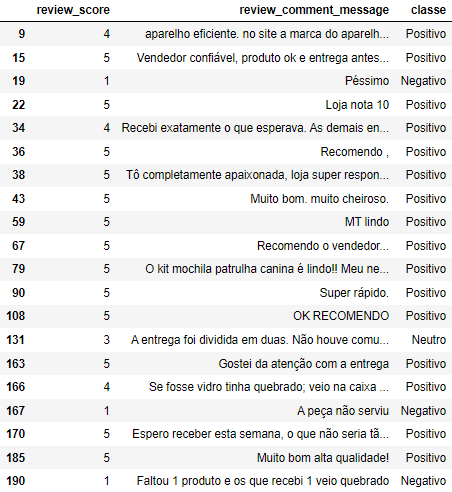
Reduzindo a variável Score para outra variável (classe)
Classificações em Pos/Neutro/Neg
# O dataset vem com uma coluna chamada "review_score", com o score de cada uma das revisões (de 1 a 5).
# Aqui adiciono a coluna "classe" para polarizar os scores em positivos, neutros e negativos.
df_copy['classe'] = [ 'Positivo' if (x>3) else 'Neutro' if (x == 3) else 'Negativo' for x in df_copy['review_score']]
df_copy.head(20)
Preparação dos dados
- Não podemos trabalhar com o texto cru, pois não funcionaria bem na hora da vetorização e aplicação de modelo estatístico
Stopwords
- Remove palavras desnecessárias que não carregam nenhum significado. Tais palavras, dentro de uma abordagem de NLP, são irrelevantes e sua remoção colaboram com a analise textual;
- Alguns exemplos de stopwords comuns no português são preposições (em, na, no, etc), artigos (a, o,os, etc), conjunções (e, mas, etc), entre outras.
def RemoveStopWords(instancia):
stopwords = set(nltk.corpus.stopwords.words('portuguese'))
palavras = [i for i in instancia.split() if not i in stopwords]
return (" ".join(palavras))
Stemming ⚠
-
Serve para diminuirmos a palavra até a sua raiz/base, pois assim, conseguimos tratar as palavras originais e suas respectivas derivações de uma mesma maneira;
-
Exemplo: As palavras Correr e Corrida quando submetidas à nossa função de Stemming, ambas as palavras serão diminuídas até a base Corr.
def Stemming(instancia):
stemmer = nltk.stem.RSLPStemmer()
palavras = []
for w in instancia.split():
palavras.append(stemmer.stem(w))
return (" ".join(palavras))
Limpeza
-
É possível fazer uma limpeza nas strings que possam “sujar” a frase e atrapalhar a análise;
-
Remove strings.
def Limpeza_dados(instancia):
# remove links, pontos, virgulas,ponto e virgulas dos tweets
instancia = re.sub(r"http\S+", "", instancia).lower().replace('.','').replace(';','').replace('-','').replace(':','').replace(')','')
return (instancia)
Lemmatization ⚠
Talvez seja mais apropriado se utilizarmos apenas Lemma ou Stemming, visto que os dois juntos podem “matar” nossas palavras.
Lematização é o processo de agrupar as diferentes formas flexionadas de uma palavra para que possam ser analisadas como um único item.
Exemplos de lematização:
-
jogar, jogo e jogador todas essas 3 palavras serão convertidas para jogo após a lematização;
-
alterar, alternância e alterado todas essas palavras serão convertidas para alteração após a lematização.
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
def Lemmatization(instancia):
palavras = []
for w in instancia.split():
palavras.append(wordnet_lemmatizer.lemmatize(w))
return (" ".join(palavras))
Criando uma função para aplicar as funções acima
def Preprocessing(instancia):
stemmer = nltk.stem.RSLPStemmer()
instancia = re.sub(r"http\S+", "", instancia).lower().replace('.','').replace(';','').replace('-','').replace(':','').replace(')','')
stopwords = set(nltk.corpus.stopwords.words('portuguese'))
palavras = [stemmer.stem(i) for i in instancia.split() if not i in stopwords]
return (" ".join(palavras))
#Aplicando a função:
df_copy['texto'] = [Preprocessing(i) for i in df_copy['review_comment_message']]
df_copy['texto'][:50]
9 aparelh efici sit marc aparelh impress 3desinf...
15 vend confiável, produt ok entreg ant praz
19 péss
22 loj not 10
34 receb exat esper demal encomend outr vend atra...
36 recom ,
38 tô complet apaixonada, loj sup respons confiável!
43 bom cheir
59 mt lind
67 recom vend
79 kit mochil patrulh canin lindo!! net vai amar!...
90 sup rápid
108 ok recom
131 entreg divid dua comunic loj cheg pens hav env...
163 gost atenç entreg
166 vidr quebr vei caix nenhum proteç dentro, caix...
167 peç serv
170 esper receb semana, tão extravagante, porémm a...
185 bom alt qualidade!
190 falt 1 produt receb 1 vei quebr
191 cheg dentr praz produt excel qualidade! acab d...
197 aqu descrev entreg ate agor receb
201 comec us agor
207 compr produt corret cap intern ser outro???????
212 fiz ped 4 garraf azeitecheg 2 dia outr 2 quas ...
228 recom
244 sup recom produt profiss qual
249 bom rap vi ja cheg
253 apes ter sid entreg rapidamente, substitu caix...
257 entreg dentr prazo, bom períod validad
276 cancel compr dia ant entrega, lig lannist aten...
279 produt qual efici entreg receb ant combin recom
281 produt bom vei dentr praz cheg 08 dia parabém
298 entreg rap
314 cad vez compr fic satisfeit parabém honest cli...
324 tud rápid efici
327 crem maravilh entreg sup rápid
332 boa noit lamentável, loj tant compr ja fiz hoj...
336 cap prote exat esper deix desej tip mater qual
341 sit produt parec ter melhor qual mater acab
345 receb produt corret dentr prazo,verific caix t...
347 parabém produt entreg bem ant prazoatend necess
391 ped cheg ant combinado, bom
394 receb apen 01 peç produto! precis 2 peç restante!
404 trabalh profission loj lannist indic cert
414 tud ok!
426 instal cartuch tinta, impres indic vazio, apre...
430 quant sit questionar! sempr cumpr sup combin r...
455 fiq feliz tec ,ma ach falt lençol cim fic comp...
479 compr ocorr esperado, desd ped receb produt tu...
Name: texto, dtype: object
type(df_copy['texto'])
pandas.core.series.Series
Tokenization
O RegexpTokenizer divide uma string em substrings usando uma expressão regular. Por exemplo, o tokenizer a seguir forma tokens de sequências alfabéticas, expressões de dinheiro e quaisquer outras sequências que não sejam espaços em branco:
from nltk.tokenize import RegexpTokenizer
s = “Bom muffins custam $3,88\nin Nova York. Por favor, compre para mim\nduas.\n\nObrigado.”
tokenizer = RegexpTokenizer('\w+|$[\d.]+|\S+’)
tokenizer.tokenize(s) [‘Bom’, ‘muffins’, ‘custo’, ‘em’, ‘Novo’, ‘York’, ‘.’, ‘Por favor’, ‘comprar’, ‘eu’, ‘dois’ , ‘de’, ‘eles’, ‘.’, ‘Obrigado’, ‘.']
import nltk
from nltk import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
## Aplicando
df_copy['texto'] = df_copy['texto'].map(tokenizer.tokenize)
df_copy['texto'].head(10)
df_copy.head(10)
Transformando os tokens em sentenças: necessário para a vetorização
## Função:
def combine_txt(t):
c = ' '.join(t)
return c
# Aplicando:
df_copy['texto'] = df_copy['texto'].apply(lambda x: combine_txt(x))
df_copy.head(10)
CountVectorizer (Matriz Esparsa)
- Ele é usado para transformar um determinado texto em um vetor (one-hot-encoded) com base na frequência (contagem) de cada palavra que ocorre em todo o texto. Envolve contar o número de ocorrências que cada palavra aparece em um documento (texto).
- O resultado deste método é uma matriz Esparsa. São matrizes nas quais a maioria das posições são preenchidas com zeros. Para essas matrizes, podemos economizar espaço de memória significativo se apenas termos diferentes de zero forem armazenados.
vectorizer = CountVectorizer(analyzer="word")
matriz = vectorizer.fit_transform(df_copy['texto'])
type(matriz)
scipy.sparse.csr.csr_matrix
matriz.shape
(9839, 6002)
# Colocando os dados em outras variáveis para facilitar a chamada
texto = df_copy['texto']
classes = df_copy['classe']
type(texto)
pandas.core.series.Series
Multinomial Naive Bayes
Naive Bayes é o algoritmo de classificação mais direto e rápido, adequado para uma grande quantidade de dados. O classificador Naive Bayes é usado com sucesso em várias aplicações, como filtragem de spam, classificação de texto, análise de sentimentos e sistemas de recomendação. Ele usa o teorema de probabilidade de Bayes para predição de classe desconhecida.
modelo = MultinomialNB()
modelo.fit(matriz,classes)
MultinomialNB()
matriz.A
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=int64)
Podemos fazer o teste do modelo em uma pequena amostra de textos
# defina instâncias de teste dentro de uma lista
testes = ['A entrega foi efetuada muito antes do prazo dado.',
'Recebi exatamente o que esperava. As demais encomendas de outros vendedores atrasaram, mas esta chegou no prazo.',
'Não recomendaria esta loja nem pretendo voltar a comprar nela.A mercadoria foi entregue após o prazo e quase 1 mês após a compra. Estranhei muito',
'Excelente produto.',
"Creme maravilhoso e entrega super rápida",
'A embalagem deixou a desejar, por pouco o produto não foi danificado, a caixa estava toda amassada.',
'Não gostei do produto, material de péssima qualidade.',
'Atendimento excelente',
'Somente foi entregue uma unidade, ao invés de duas.',
'Fiquei feliz com. O tecido ,mas acho que faltou o lençol de cima para ficar completo, espero que logo lancem.',
'A bolsa e muito bonita por fora. Mas dentro não tem forro e é bem fragil',
'Fonte veio diferente do anunciado.',
'Produto com funcionamento correto, porem qualidade do material muito baixa.',
'Frete muito caro.',
'Produto Maravilhoso, exatamente como anunciado! Amei e já coloquei! Recomendo muito!',
'é muito desordenado comprei três produtos mais não veio no dia sertões veio separado e em data separada']
testes = [Preprocessing(i) for i in testes]
matriz_teste = vectorizer.transform(testes)
# Fazendo a classificação com o modelo treinado:
for t, c in zip (testes,modelo.predict(matriz_teste)):
print (t +", "+ c)
entreg efetu ant praz dad, Positivo
receb exat esper demal encomend outr vend atrasaram, cheg praz, Positivo
recomend loj pret volt compr nela mercad entreg após praz quas 1 mê após compr estranh, Negativo
excel produt, Positivo
crem maravilh entreg sup rápid, Positivo
embal deix desejar, pouc produt danificado, caix tod amass, Neutro
gost produto, mater péss qual, Positivo
atend excel, Positivo
soment entreg unidade, invé dua, Negativo
fiq feliz tec ,ma ach falt lençol cim fic completo, esper log lanc, Negativo
bols bonit dentr forr bem fragil, Positivo
font vei difer anunci, Negativo
produt funcion correto, por qual mater baix, Positivo
fret car, Positivo
produt maravilhoso, exat anunciado! ame coloquei! recom muito!, Positivo
desorden compr trê produt vei dia sert vei separ dat separ, Negativo
# Probabilidades de cada classe na análise acima
print (modelo.classes_)
modelo.predict_proba(matriz_teste).round(2)
['Negativo' 'Neutro' 'Positivo']
array([[0. , 0. , 0.99],
[0.01, 0. , 0.98],
[0.94, 0. , 0.06],
[0. , 0. , 1. ],
[0. , 0. , 1. ],
[0.21, 0.59, 0.2 ],
[0.34, 0.02, 0.64],
[0. , 0. , 1. ],
[0.98, 0.01, 0.01],
[0.54, 0.42, 0.04],
[0. , 0.01, 0.99],
[0.63, 0.07, 0.3 ],
[0.05, 0.02, 0.93],
[0.16, 0.19, 0.65],
[0. , 0. , 1. ],
[0.7 , 0.1 , 0.21]])
Tag de Negações
- Acrescenta uma tag _NEG encontrada após um ‘não’.
- Objetivo é dar mais peso para o modelo identificar uma inversão de sentimento da frase.
- Exemplos:
- Eu não gosto do partido e também nunca votaria nesse governante!
~ Eu não gosto_NEG do_NEG partido_NEG e_NEG também_NEG nunca_NEG votaria_NEG nesse_NEG governante!_NEG
- Eu não gosto do partido e também nunca votaria nesse governante!
def marque_negacao(texto):
negacoes = ['não','not']
negacao_detectada = False
resultado = []
palavras = texto.split()
for p in palavras:
p = p.lower()
if negacao_detectada == True:
p = p + '_NEG'
if p in negacoes:
negacao_detectada = True
resultado.append(p)
return (" ".join(resultado))
Criando modelos com Pipelines
- Pipelines são interessantes para reduzir código e automatizar fluxos
from sklearn.pipeline import Pipeline
pipeline_simples = Pipeline([
('counts', CountVectorizer()),
('classifier', MultinomialNB())
])
- Pipeline que atribui tag de negacões nas palavras
pipeline_negacoes = Pipeline([
('counts', CountVectorizer(tokenizer=lambda text: marque_negacao(text))),
('classifier', MultinomialNB())
])
pipeline_simples.fit(texto,classes)
Pipeline(steps=[('counts', CountVectorizer()), ('classifier', MultinomialNB())])
- Etapas do pipeline
pipeline_simples.steps
[('counts', CountVectorizer()), ('classifier', MultinomialNB())]
pipeline_negacoes.fit(texto,classes)
Pipeline(steps=[('counts',
CountVectorizer(tokenizer=<function <lambda> at 0x0000027A53AF0310>)),
('classifier', MultinomialNB())])
pipeline_negacoes.steps
[('counts',
CountVectorizer(tokenizer=<function <lambda> at 0x0000027A53AF0310>)),
('classifier', MultinomialNB())]
- Modelo com SVM
pipeline_svm_simples = Pipeline([
('counts', CountVectorizer()),
('classifier', svm.SVC(kernel='linear'))
])
pipeline_svm_negacoes = Pipeline([
('counts', CountVectorizer(tokenizer=lambda text: marque_negacao(text))),
('classifier', svm.SVC(kernel='linear'))
])
Validando os Modelos com Validação Cruzada
- Fazendo o cross validation do modelo
resultados = cross_val_predict(pipeline_simples, texto, classes, cv=10)
- Medindo a acurácia média do modelo
metrics.accuracy_score(classes,resultados)
0.8373818477487549
- Medidas de validação do modelo
sentimento=['Positivo','Negativo','Neutro']
print(metrics.classification_report(classes,resultados,sentimento))
#dados neutros com precisão baixa (pouca amostra ou é difícil pro modelo identificar uma frase "neutra"?)
precision recall f1-score support
Positivo 0.89 0.94 0.91 6855
Negativo 0.72 0.78 0.75 2247
Neutro 0.22 0.04 0.07 737
accuracy 0.84 9839
macro avg 0.61 0.59 0.58 9839
weighted avg 0.80 0.84 0.81 9839
- Matriz de confusão: nos permite analisar onde o algoritmo está errando com maior frequência
print(pd.crosstab(classes, resultados, rownames=['Real'], colnames=['Predito'], margins=True))
Predito Negativo Neutro Positivo All
Real
Negativo 1751 41 455 2247
Neutro 342 29 366 737
Positivo 335 61 6459 6855
All 2428 131 7280 9839
def Metricas(modelo, texto, classes):
resultados = cross_val_predict(modelo, texto, classes, cv=10)
return 'Acurácia do modelo: {}'.format(metrics.accuracy_score(classes,resultados))
Naive Bayes
# naive bayes simples
Metricas(pipeline_simples,texto,classes)
'Acurácia do modelo: 0.8373818477487549'
# naive bayes com tag de negacoes (piorou com o uso de negações)
Metricas(pipeline_negacoes,texto,classes)
'Acurácia do modelo: 0.711556052444354'
Support Vector Machine (SVM) ~ (funciona melhor ainda com dados binários)
- É um algoritmo de aprendizado de máquina supervisionado que pode ser usado para desafios de classificação ou regressão. Analisa os dados e reconhece padrões. Linear SVM é o mais novo algoritmo de aprendizado de máquina (mineração de dados) extremamente rápido para resolver problemas de classificação multiclasse de conjuntos de dados ultra grandes que implementa uma versão proprietária original de um algoritmo de plano de corte para projetar uma máquina de vetor de suporte linear. LinearSVM é uma rotina linearmente escalável, o que significa que ela cria um modelo SVM em um tempo de CPU que escala linearmente com o tamanho do conjunto de dados de treinamento.
# svm linear simples
Metricas(pipeline_svm_simples,texto,classes)
'Acurácia do modelo: 0.8296574855168208'
# svm linear com tag de negacoes (é bem mais demorado, pois as palavras que estão após um NÃO irão duplicar)
Metricas(pipeline_svm_negacoes,texto,classes)
'Acurácia do modelo: 0.7478402276654131'
Modelo com a Tag de Negações
resultados = cross_val_predict(pipeline_negacoes,texto, classes, cv=10)
metrics.accuracy_score(classes,resultados)
0.711556052444354
sentimento=['Positivo','Negativo','Neutro']
print (metrics.classification_report(classes,resultados,sentimento))
precision recall f1-score support
Positivo 0.73 0.96 0.83 6855
Negativo 0.55 0.19 0.28 2247
Neutro 0.09 0.01 0.02 737
accuracy 0.71 9839
macro avg 0.46 0.39 0.38 9839
weighted avg 0.64 0.71 0.64 9839
- Matriz de confusão
# Podemos comparar o resultado das duas matrizes e verificar em quais ele acertou mais em cada classe
# Nesta segunda matriz podemos ver que o modelo acertou bem menos em negativo com a tag de negações
print (pd.crosstab(classes, resultados, rownames=['Real'], colnames=['Predito'], margins=True))
Predito Negativo Neutro Positivo All
Real
Negativo 430 62 1755 2247
Neutro 97 9 631 737
Positivo 261 32 6562 6855
All 788 103 8948 9839
Considerações Finais
É possível implementar nosso modelo com alguns adicionais, como:
- Aumentar features (temos bag of words), poderíamos aumentar a quantidade de palavras, considerar emojis;
- Dados binários fluem muito bem com SVM, apesar do algoritmo ter funcionado um pouco melhor que NB com nossas 3 classes;
- Tomar cuidado com as opções Lemmatizer e Stemming, elas podem confundir o modelo se utilizadas incorretamente.